今回はfirst, last↔SORT NODUPKEYの変換について解説します。
結論を先に書くと、変換できる場合、変換できない場合とがあります。
/*sort1*/
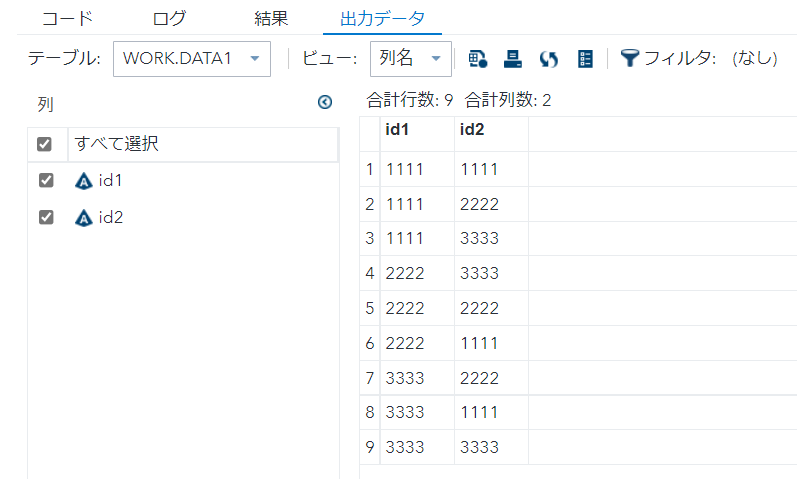
data data1;
id1="1111"; id2="1111";
output;
id1="1111"; id2="2222";
output;
id1="1111"; id2="3333";
output;
id1="2222"; id2="3333";
output;
id1="2222"; id2="2222";
output;
id1="2222"; id2="1111";
output;
id1="3333"; id2="2222";
output;
id1="3333"; id2="1111";
output;
id1="3333"; id2="3333";
output;
run;
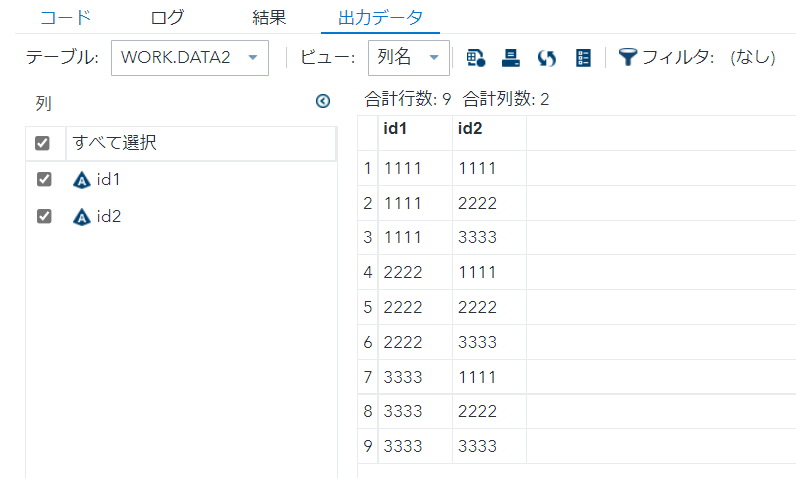
proc sort data=data1 out=data2 ; by id1 id2 ; run;
data data3; set data2; by id1 id2;
if first.id2 = 1;
run;
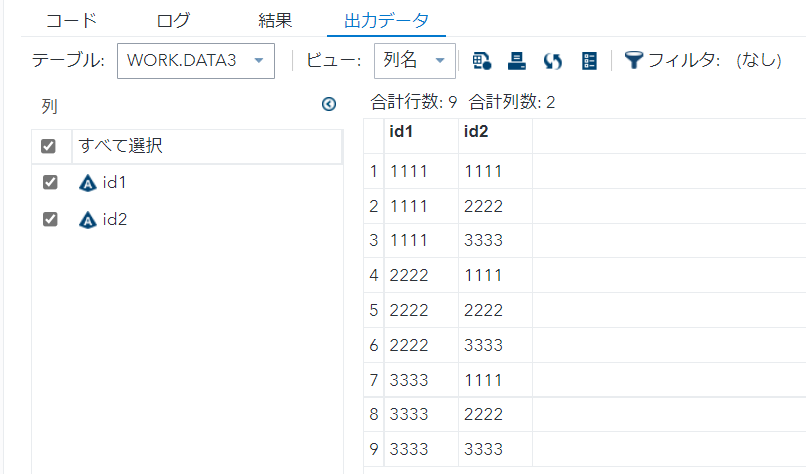
ソート⇒ユニークをnodupkeyで表すと、
/* nodupkey1 */
proc sort nodupkey data=data1 out=data3 ; by id1 id2 ; run;
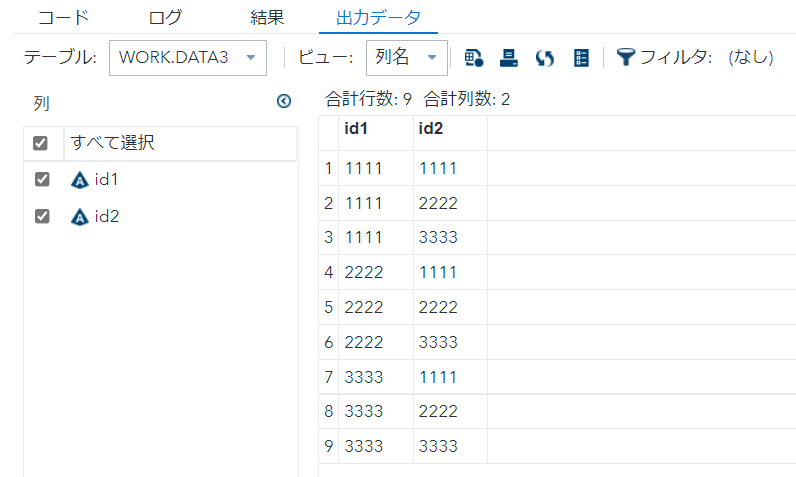
このようにソート⇒ユニークの流れはnodupkeyで書き表すことができます。
続いて、sort2
/*sort2*/
data data1;
id1="1111"; id2="1111";
output;
id1="1111"; id2="2222";
output;
id1="1111"; id2="3333";
output;
id1="2222"; id2="3333";
output;
id1="2222"; id2="2222";
output;
id1="2222"; id2="1111";
output;
id1="3333"; id2="2222";
output;
id1="3333"; id2="1111";
output;
id1="3333"; id2="3333";
output;
run;
proc sort data=data1 out=data2 ; by id1 id2 ; run;
data data3; set data2; by id1 id2;
if first.id1 = 1;
run;
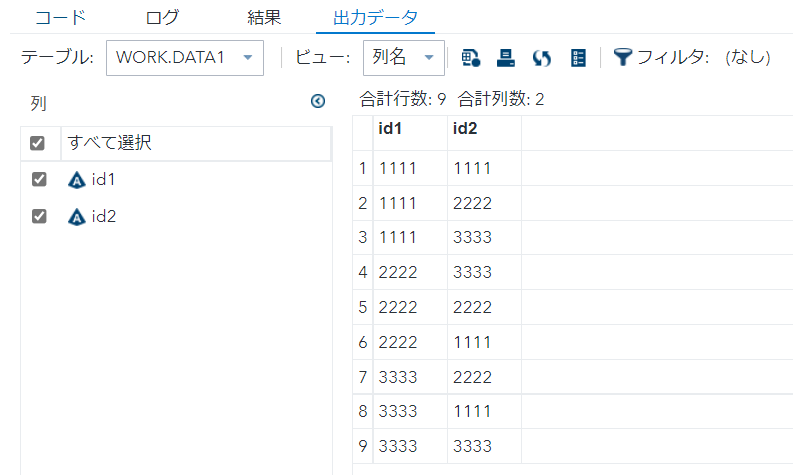
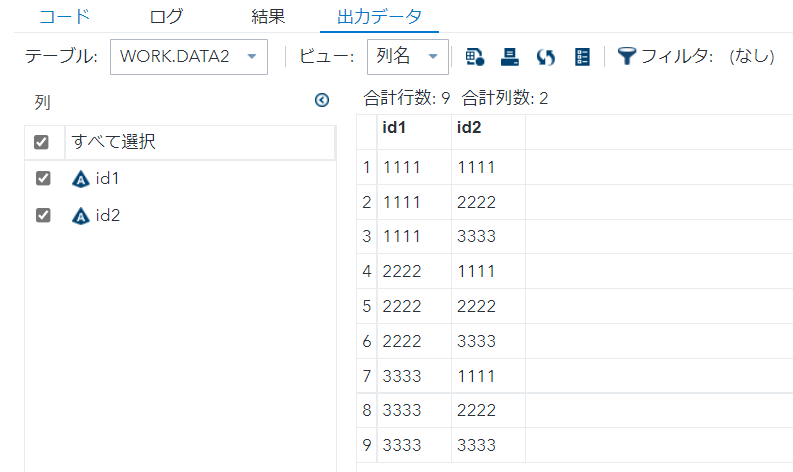

このソート⇒ユニークの流れをnodupkeyで書き表そうとすると、
/* nodupkey2_1 */
proc sort nodupkey data=data1 out=data3 ; by id1 id2 ; run;
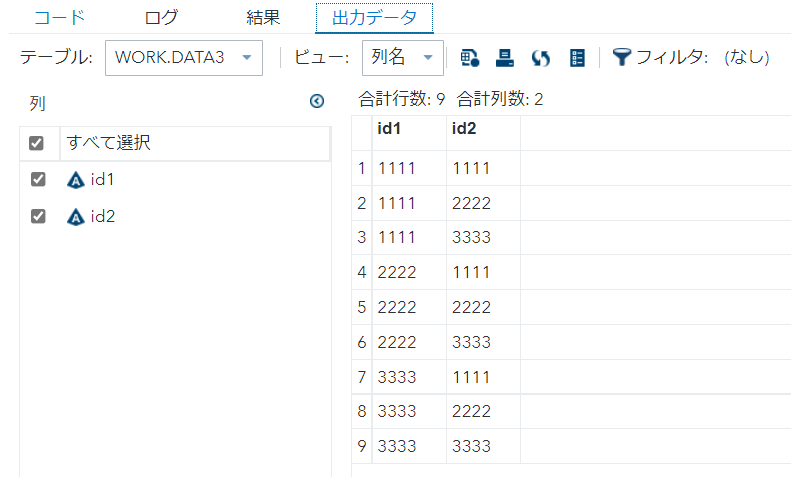
上記のnodupkey2_1では不適切なことが分かります。
/* nodupkey2_2 */
proc sort nodupkey data=data1 out=data3 ; by id1 ; run;
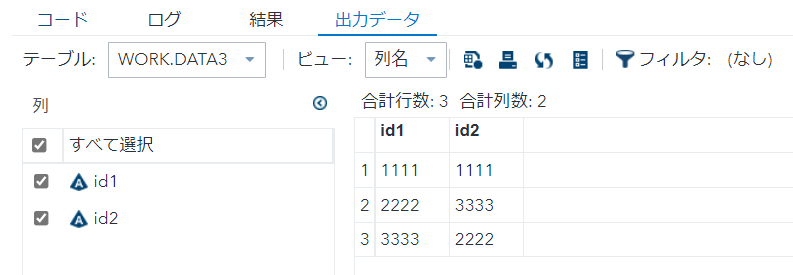
nodupkey2_2でも無いことが分かります。
/* nodupkey2_3 */
proc sort nodupkey data=data1 out=data3 ; by id2 ; run;
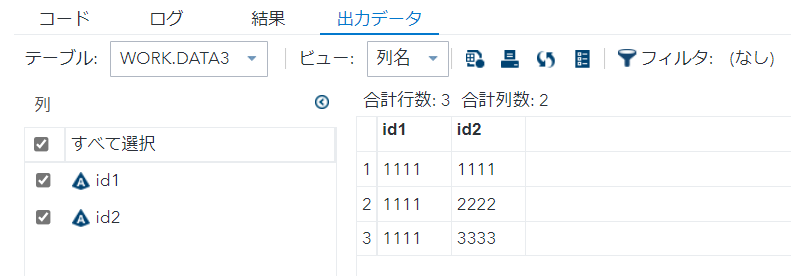
nodupkey2_3でも無いことが分かります。
/* nodupkey2_4 */
proc sort nodupkey data=data1 out=data3 ; by descending id1 ; run;
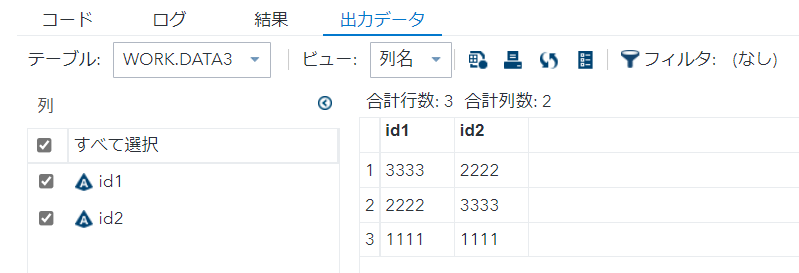
nodupkey2_4でも無いことが分かります。
/* nodupkey2_5 */
proc sort nodupkey data=data1 out=data3 ; by descending id2 ; run;
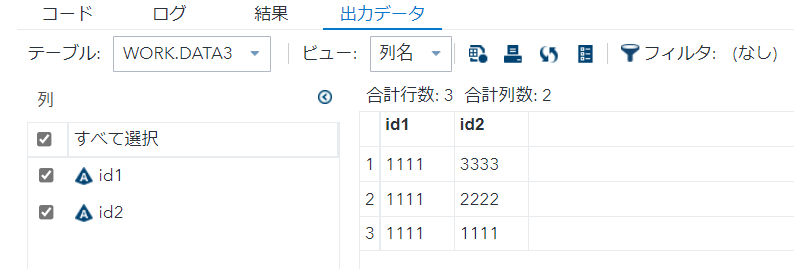
nodupkey2_5でも無いことが分かります。
まとめると、ソートキーとユニークキーが同一の場合は変換できます。
異なる場合は変換できない場合があります。

