今回はNODUPについて解説します。
前回NODUPKEYについて解説しました。
今回のNODUPは前回の文法の亜種という感じです。
/*nodup1*/
data data1;
id="A"; chiku="SHINJUKU1"; 数字=1;
output;
id="A"; chiku="SHINJUKU1"; 数字=1;
output;
id="A"; chiku="SHINJUKU2"; 数字=3;
output;
id="B"; chiku="ICHIGAYA1"; 数字=4;
output;
id="B"; chiku="ICHIGAYA1"; 数字=4;
output;
id="B"; chiku="ICHIGAYA2"; 数字=6;
output;
id="C"; chiku="SHIBUYA"; 数字=7;
output;
run;
proc sort data=data1 out=data2 nodup; by id chiku; run;
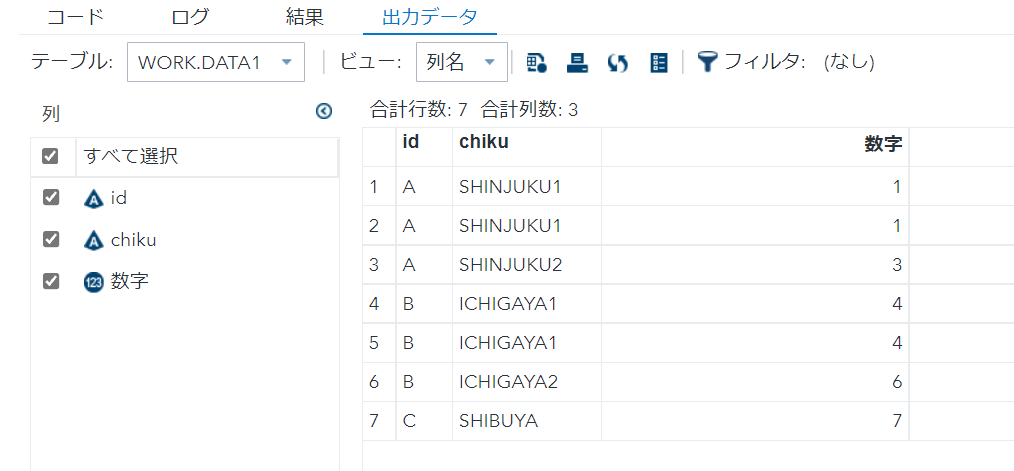
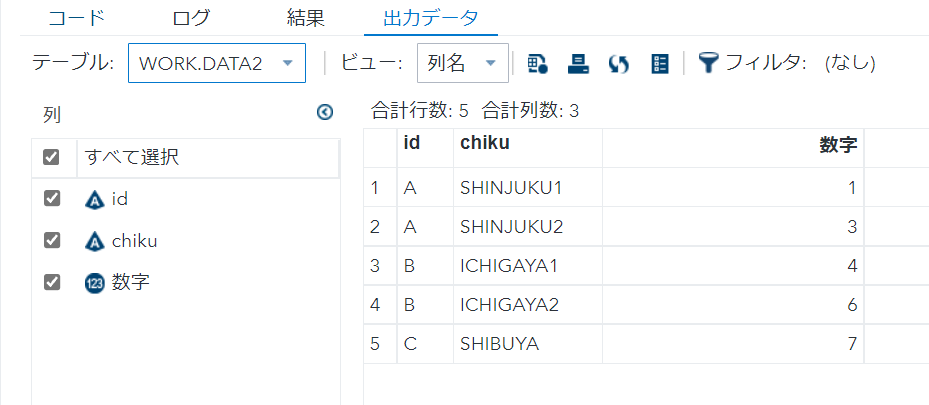
- nodupはキー重複を除き、先頭行のみ出力する。
- 全ての変数で重複を見る。
/*nodup2*/
data data1;
id="A"; chiku="SHINJUKU1"; 数字=1;
output;
id="A"; chiku="SHINJUKU1"; 数字=2;
output;
id="A"; chiku="SHINJUKU2"; 数字=3;
output;
id="B"; chiku="ICHIGAYA1"; 数字=4;
output;
id="B"; chiku="ICHIGAYA1"; 数字=5;
output;
id="B"; chiku="ICHIGAYA2"; 数字=6;
output;
id="C"; chiku="SHIBUYA"; 数字=7;
output;
run;
proc sort data=data1 out=data2 nodup; by id chiku; run;

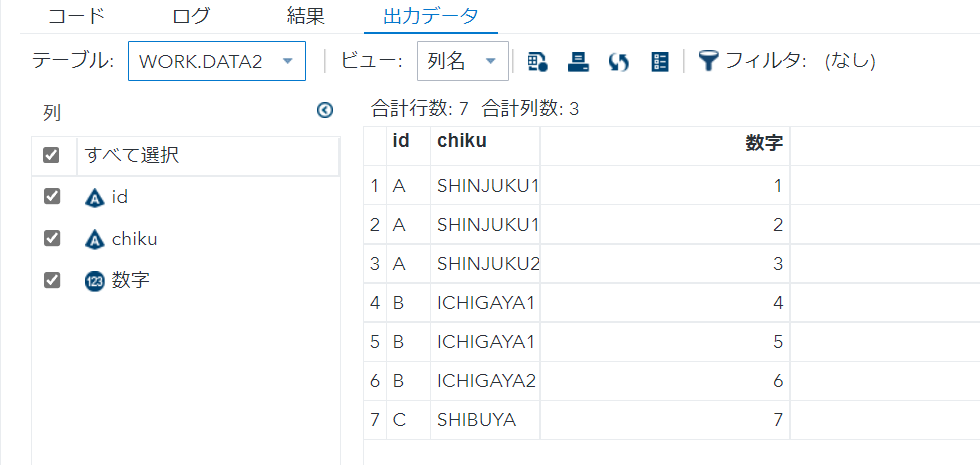
- nodupはキー重複を除き、先頭行のみ出力する。
- 全ての変数で重複を見る。

